

人に寄り添い、
社会に対応する人工知能システム
人工知能先端研究センター(AIX、Artificial Intelligence eXploration Research Center)は2016年に国立大学で初の人工知能研究拠点として設立された。基本理念に「AI for X」を掲げ、「人工知能(AI)を探究し連鎖させ爆発的に社会を発展させる」ことを目指す。 「科学のためのAI」「デザインのためのAI」「サービスのためのAI」を3本柱に、その共通基盤となる「汎用型AIの開発」を研究の主軸とする。脳神経科学、高次元データ駆動科学、複雑ネットワーク、機械学習、深層学習、自然言語・画像・音声処理、ロボティクス、介護や日常生活サポートロボット、教育工学、計算社会科学、サービス・サイエンスなど広範な分野の研究者が多数在籍する。

センター長を務める南泰浩教授は「人工知能はさまざまに定義されますが、人工知能の研究とは、人間にできて機械にできないことを研究することです。電卓は人工知能として開発されましたが、今は誰も人工知能とは考えない身近なものになっています。人間と同じような能力を持った機械ができたとき、その機械をもう人工知能とは呼ばないとする考え方に強い共感を覚えます。複数のシステムの協調、人間の高度な認知や学習活動を検証することをはじめ多岐にわたる研究を展開、統合して、汎用人工知能と呼ばれる何でもできる人工知能を目指したい」とビジョンを語る。
「これから先、いろいろなところで、さまざまなものがつながる世界が考えられます。それでも今は人間にできて機械にできないことが山のようにあります。既に世の中のいろいろなものがつながって、たくさんのデータが集められ、さまざまなサービスが生まれていますが、私たちはその先を目指していきたいのです」と話し、人間社会に寄り添い、人と共生して、心と体に自然に対応する人工知能システムの実現に向けて歩みを進めている。

言葉で自然に対話するコンピュータを目指す
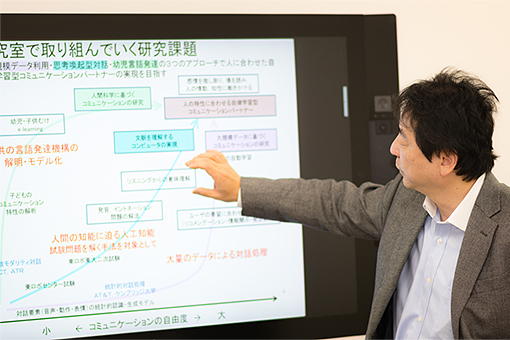
自然にコミュニケーションできるコンピュータ。南教授はそれを目指して研究を行っている。「コンピュータが人間と自然な会話ができれば、多くの人がコンピュータを自由に使うことができます。その実現のために、幼児が言葉を覚える仕組みの解明、雑談のように人と自然な対話ができるシステムの開発、試験問題を解くなど人間の高度な知識処理を実現する人工知能の開発という3つの分野に重点を置いて研究を進めています」
南教授は1980年代から音声認識の研究に携わり、スマートフォンに搭載されている対話型システムのAPIの開発などにも関わり,この分野で先駆的な役割を果たした。同時に人間の語彙獲得機能の研究にも乗り出し、心理学的アプローチによる長期的な横断・縦断データを活用して数理的なモデルを構築し、人間がどのようにして言語を習得するかという謎に迫っている。
「言葉を覚え始めたお子さんが1日にどれくらい言葉を覚えるかを調べたところ、言葉を覚える時期と覚えていない時期が明確に分かれ、繰り返されていました。心理学でよくいわれる学習休止期(プラトー)であることに気づき、獲得した語彙数を表すグラフからプラトーの時期を取り除くと、一定の右肩上がりになったきれいな直線でつながりました。つまり言葉を覚える速度は一定だったのです。1歳頃に語彙を爆発的に獲得するとされていましたが、ある時期にプラトーがなくなると、語彙が爆発的に増えるように見えていたのでしょう。お子さんごとに言葉を覚える速度は異なりますが、詳しく調べると、最初に覚える20単語くらいの品詞の種類と強い相関があることも分かりました」
南教授らによる研究はさらに進められ、昨年11月には、言語発達停滞、自閉症スペクトラム、ダウン症、知的障害、筋ジストロフィなど非定型発達児の獲得語彙の順序やタイプを大規模データ解析によって明確化し、定型発達児と同様のプロセスをたどる傾向にあることを発表している。
人間の知能に迫る人工知能
「未知の物体がある。そこには特徴量と呼んでいる色、形、触感、におい、触感など、物体に付随しているさまざまな特性や特徴があります。幼児はある特徴量を選択することで、何であるのかを識別、判断していきます。そして犬が4本足であるということを覚えた幼児は、4本足の動物であれば何を見ても犬だとすることがありますが、猫などが示されるうちにだんだんと情報の選択などを分化させていきます。そういった仕組みをコンピュータでモデル化する取り組みを進めています」

南教授はこれまで「ロボットは東大に入れるか」という国立情報学研究所のプロジェクトに携わり、英語の教科を担当して発音問題で高得点を獲得し、意見要旨把握も担当し,他の研究機関の会話文完成、未知の語句の意味推測、語句整序完成などの正答率の向上にも貢献している。コンピュータによる対話処理の研究では、従来のような認識精度の向上を図るパターン認識にとどまらず、人間とシステムとの関係の自然性の向上を主眼に置く。
「言葉は音声、語彙、文法、文脈・意味と大きく4つに分けることができ、コンピュータが最も苦手としているのが文脈・意味の理解です。人間が通常で覚えている語彙数は30万、40万語といわれますが、人工知能は1日か2日で10億単語も覚えてしまいます。それでも雑談型の対話では、一つ一つは一見まともな返答になっていても、前に言った内容との一貫性がないなど、矛盾ということをうまく理解することができません。人間は話し相手のバックグランドを考えて話すことができますが、学習データを使って対話するコンピュータはそうではありません、学習データには一般常識に相当するものが多くないのです。人間の言語習得の仕組みを解き明かしながら、人間の知能に迫る人工知能を作り上げたいと考えています」